UseMembar?
这一篇文章的切入口是 JVM 中的 UseMembar 参数,并依此聊一聊对 Store Buffer 的粗浅理解,如有不当之处欢迎指正。
注:读者最好提前了解了缓存一致性协议的相关知识
写屏障的概念
这里回顾一下 MESI协议
MESI 是四个单词的缩写,每个单词分别代表缓存行的一个状态:
- M:modified,已修改。缓存行与主存的值不同。如果别的 CPU 内核要读主存这块数据,该缓存行必须回写到主存,状态变为共享状态(S)。
- E:exclusive,独占的。缓存行只在当前缓存中,但和主存数据一致。当别的缓存读取它时,状态变为共享;当前写数据时,变为已修改状态(M)。
- S:shared,共享的。缓存行也存在于其它缓存中且是干净的。缓存行可以在任意时刻抛弃。
- I:invalid,无效的。缓存行是无效的。
当 CPU0 发生Store操作时,如果这个数据不在私有缓存里,那么 CPU0 就会发送一个 Read + Invalidate 消息去读取对应的数据,并让其他的缓存副本失效。其他 CPU 收到 Invalidate 消息 完成对应缓存副本的失效操作后,其他 CPU 向 CPU0 发送 Invalidate Acknowledge 信息。等 CPU0 收到所有其他 CPU 响应的 Invalidate Acknowledge 信息后,再将数据写入 CPU0 的缓存。CPU0 等待其他 CPU 响应的 Invalidate Acknowledge 信息,这段时间是一种浪费。
为了减少这种等待,就引入了 Store Buffer,结构如下图:
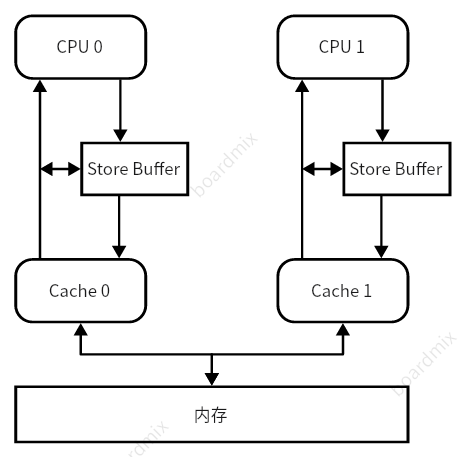
引入了 Store Buffer 确实能够解决一部分等待时间长的问题,但是也破坏了内存的一致性,考虑这个经典的案例(忽略 cache 与 内存的交互过程):
1 | |
假设:CPU0 只缓存了 b,因为是独占,所以状态是 E。CPU1 只缓存了 a,同样是独占状态 E。
- CPU0 执行 a=1,因为 a 不在 CPU0 的 cache 中,有 store buffer 的存在,直接写将 a=1 写到 store buffer,同时发送一个 read invalidate 消息。
(此时状态:CPU0 认为完成了 a=1,可以进行 b=1 操作) - CPU0 执行 b=1,因为 b 在 CPU0 的 cache 中,且状态为独占 E,直接将 b 的 cache 行设置为已修改 M,并将新值写入 cache
(此时状态:invalidate 消息还没有被传到 CPU1,CPU1 的 cache 中 a 的值依旧为 0;自然也没有回传 Invalidate Acknowledge 信息,a 的新值 1 依旧在 CPU0 的 store buffer 中) - CPU1 执行 while(b==1),因为 b 不在 CPU1 的缓存中,所以 CPU1 发送一个 read 消息去读。
- CPU0 收到 CPU1 的 read 消息,知道 CPU1 想要读 b,于是返回一个 read response 消息,同时将对应缓存行的状态改成 S。
- CPU1 收到 read response 消息,知道 b=1,于是将 b=1 放到缓存,同时结束 while 循环。
- CPU1 执行 assert(a==1),从 CPU1 的 cache 看 CPU1 独占 a ,直接拿到 a=0,assert 失败。
指令乱序的简化理解:从 CPU0 的角度 a=1 先于 b=1;从 CPU1 的角度看 CPU0 b=1 先于 a=1。
为了消除这种乱序问题,硬件设计师为软件开发者提供了写屏障 smp_wmb(),写屏障的直观目的是为了保障 a=1 写入cache 之后才能将 b=1 写入 cache。
1 | |
通过上述方式能规避指令乱序带来的问题。
UseMembar 应用场景
为什么会讲到这个小例子,因为 Hotspot 中 UseMembar 的应用场景和小例子很相似。假设平台单核单线程,存在如下情况
1 | |
很显然,这种情况与上一节的小例子几乎可以说一模一样。那么也会出现相似的乱序问题,也可以通过添加内存写屏障的方式来避免,如下:
1 | |
这种情况就是 UseMembar 开启的情况
伪内存屏障
很显然当 Thread 0 高频次交替运行 Java 方法和 Native 方法,而 Thread 1 仅少量次数调用 bar() 方法时,写内存屏障的存在就只能带来性能上的损耗,回到开头的小例子:
1 | |
考虑第二种处理方式(对应-XX:-UseMembar),我们是不是可以考虑不添加写屏障,变为只在 assert(a == 1) 之前,保证所有其他 CPU 接受到 Invalidate 消息,这样也能保证正确性。实际上 CPU1 并不知道有没有没收到的 Invalidate 消息,那么索性将要读的值 a 置为 invalid 状态,但这又引来了新问题,需要保证所有 store buffer 中的 a 的值刷到内存上。即变为如下情况
1 | |
这里的 serialize_thread_states() 函数的函数名延用了 Hotspot 中的名字,实现的效果是将 a 在 cache 中状态变为 invalid。我们来看看 Hotspot 中的实现逻辑:
1 | |
在 Hotspot 中将提供上述四步完成,步骤 1 和 4 将内存页 P 上锁,避免在修改权限时有新的数据写入;步骤 2 完成将 store buffer 中信息刷入 cache 的操作;步骤 3 单纯将权限修改回写读。其中,改变内存页权限的函数为内核函数 mprotect。mprotect 函数的解析可以参考《mprotect do memory barrier on SMP》
mprotect 的本意是用来更改 Page 的属性 - 读、写、执行等页属性。它有一个副作用,就是更改页属性后,OS 会向各 CPU 发送 IPI 中断来失效处理器的 TLB (Translation Lookaside Buffer) 和 cache-line ,并为每个 CPU 添加 write memory barrier ,保证 Page 属性修改前对应页的本地 store buffer 刷新到内存。
从处理上不难看出,伪内存屏障的处理更加损耗性能,那为什么还要提出这种处理方式呢,原因就在于方法调用的频次。当CPU0 调用 foo 方法的次数非常多时,伪内存屏障优化就会出现反效果。
UseMembar 如何选择
如何选择是否开启 UseMembar 选项,一方面需要考虑 Hotspot 运行的平台上内存屏障的性能损耗(可能出现使用内存屏障性能损耗非常小,不构成性能瓶颈的情况)。另一方面需要判断伪内存屏障被调用频次多不多的问题,考虑如下两种情况。
情况1:安全点
正常需要进入安全点时,会将safepoint _state(_synchronizing)写入某处,然后所有可以进入安全点的线程会去同一个地方读取标志,来实现进入Safepoint的操作。但是需要注意,如果线程的状态是 _thread_in_native即线程处运行在native code时,不需要等待该线程的阻塞,如果由于写读乱序导致了意外的STW,不会影响正确性。但是当native方法退出时,需要将线程的状态设置为 _thread_in_native_trans,这一步必须在Safepoint开始之前完成,否则会出错!!
所以将_thread_in_native_trans状态写入线程状态的操作与将_synchronizing状态写入内存的操作顺序需要保证在多核(is_MP)运行情况下一致!!
此时有两种实现方式
- 在写入
_thread_in_native_trans状态之后添加内存写屏障,保证写入正确(-XX:+UseMembar) - 将
_thread_in_native_trans状态写入serialize_page页,通过改变serialize_page页写读权限
(伪内存屏障-XX:-UseMembar)
考虑到进 safepoint 的频次要小于 Native Java 方法切换的频次,可以考虑使用伪内存屏障(-XX:-UseMembar)
情况2:JFR Method Profiling
JFR 的 方法采样事件分为 Java 方法采样与Native 方法采样,在暂停线程之前需要判断被采样线程的线程状态,也需要保证_thread_in_native_trans状态已经写入线程状态。如果是 -XX:-UseMembar 状态则也会在判断前调用伪内存屏障,考虑到方法采样的频次会很高,这时候频繁调用伪内存屏障就成了 JFR 给应用程序带来的性能损耗的主要部分。所以,此时应该考虑使用物理屏障(-XX:+UseMembar)。
参考
《关于缓存一致性协议、MESI、StoreBuffer、InvalidateQueue、内存屏障、Lock指令和JMM的那点事》
《内存屏障今生之Store Buffer, Invalid Queue》
《mprotect do memory barrier on SMP》
[《Adventures with Memory Barriers and Seastar on Linux》]